27.01 Поиск центроида
Ошибка.
Попробуйте повторить позже
Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба, а
также по блеску звезды. Кластер звёзд – это набор звёзд (точек) на графике, лежащий внутри круга радиуса  .
Каждая звезда, подходящая под заданный уровень блеска, обязательно принадлежит только одному из кластеров.
Остальные звёзды не относятся к рассматриваемым кластерам.
.
Каждая звезда, подходящая под заданный уровень блеска, обязательно принадлежит только одному из кластеров.
Остальные звёзды не относятся к рассматриваемым кластерам.
Истинная периферия кластера, или перифероид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера максимальна.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости,
которое вычисляется по формуле:
на плоскости,
которое вычисляется по формуле:

Аномалиями назовём точки, находящиеся на расстоянии более  условных единиц от точек кластеров. При
расчётах аномалии учитывать не нужно.
условных единиц от точек кластеров. При
расчётах аномалии учитывать не нужно.
В файле A хранятся данные о звёздах шести кластеров, где  для каждого кластера, а звёзды обладают
блеском условных единиц, целая часть которых четна. В каждой строке записана информация об уровне блеска звезды,
а также о расположении на карте одной звезды: сначала координата
для каждого кластера, а звёзды обладают
блеском условных единиц, целая часть которых четна. В каждой строке записана информация об уровне блеска звезды,
а также о расположении на карте одной звезды: сначала координата  , затем координата
, затем координата  и наконец уровень
блеска
и наконец уровень
блеска  . Значения даны в условных единицах, которые представлены вещественными числами. Известно, что
количество звёзд не превышает 3000.
. Значения даны в условных единицах, которые представлены вещественными числами. Известно, что
количество звёзд не превышает 3000.
В файле Б хранятся данные о звёздах трех кластеров, где  для каждого кластера, а звёзды обладают блеском
условных единиц, целая часть которых нечетна. Известно, что количество звёзд не превышает 20000. Структура
хранения информации о звездах в файле Б аналогична файлу А.
для каждого кластера, а звёзды обладают блеском
условных единиц, целая часть которых нечетна. Известно, что количество звёзд не превышает 20000. Структура
хранения информации о звездах в файле Б аналогична файлу А.
Для каждого файла определите координаты периферии каждого кластера, затем вычислите два числа:  —
среднее арифметическое абсцисс периферий кластеров, и
—
среднее арифметическое абсцисс периферий кластеров, и  – среднее арифметическое ординат периферий
кластеров.
– среднее арифметическое ординат периферий
кластеров.
В ответе запишите четыре числа через пробел: сначала целую часть  для файла А и
для файла А и  для файла А, далее
целую часть произведения
для файла А, далее
целую часть произведения  для файла Б и
для файла Б и  для файла Б.
для файла Б.
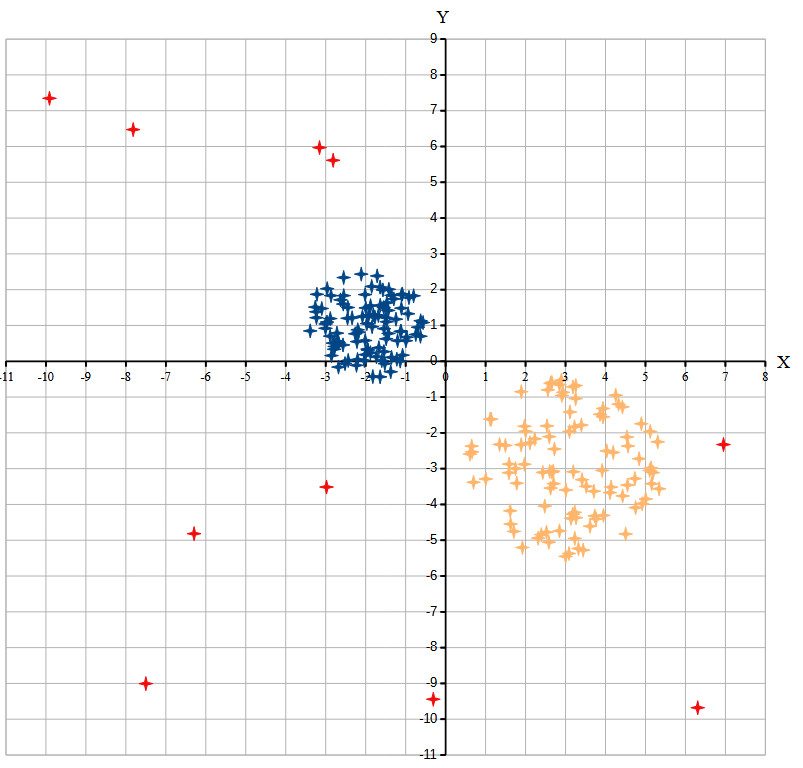
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.

Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  ,
перейдем в раздел «Вставка
,
перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
Диаграмма для файла А имеет вид:
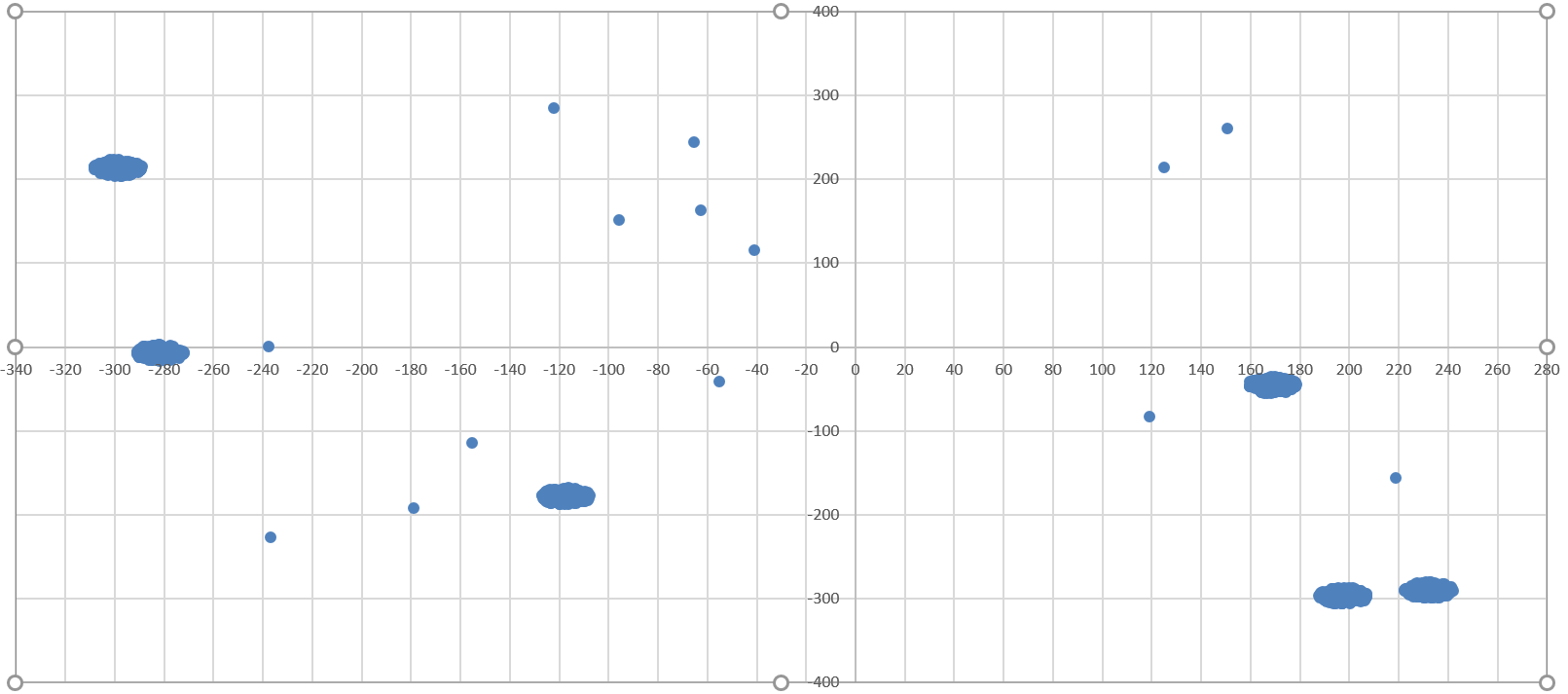
Рассмотрим 6 кластеров и координаты, в которых они находятся:
1) 
2) 
3) 
4) 
5) 
6) 
Код программы для файла А:
f = open(’5A.txt’)
n = f.readline() # Считываем первую строку файла с названиями столбцов
#распределение звезд на кластеры с помощью метода dbscan
# сохраняем массив данных
st = [list(map(float, i.replace(’,’, ’.’).split())) for i in f]
# подбираем по 1 звезде для каждого кластера меняя параметры в скобках
# for i in range(len(st)):
# if (215 < st[i][0] < 250 and -200 > st[i][1]) and int(st[i][2]) % 2 == 0:
# print(i)
# break
a = [[[st[338][0], st[338][1]]], [[st[1332][0], st[1332][1]]], [[st[2][0], st[2][1]]], [[st[999][0], st[999][1]]], [[st[1666][0], st[1666][1]]], [[st[666][0], st[666][1]]]]
st.pop(1666), st.pop(1332), st.pop(999), st.pop(666), st.pop(338), st.pop(2)
# отсеиваем все звезды с неподходящим блеском
for i in range(len(st)):
if int(st[i][2]) % 2 != 0:
st[i] = ’*’
# разделяем звезды на кластеры методом dbscan
for k in range(6):
for j in a[k]:
for i in range(len(st)):
if st[i] != ’*’:
p = [st[i][0], st[i][1]]
if dist(p, j) < 10 and int(st[i][2]) % 2 == 0:
a[k].append(p)
st[i] = ’*’
# распределение звезд на кластеры с помощью координат
a = [[] for i in range(6)] # Создаём список для кластеров
for line in f: # Считваем звёзды и определяем их к кластерам
x, y, m = list(map(float, line.replace(’,’, ’.’).split()))
if int(m) % 2 == 0:
if (x < -280) and (y > 150):
a[0].append([x, y])
elif (x < -260) and (-50 < y < 50):
a[1].append([x, y])
elif (-140 < x < -100) and (-200 < y < -150):
a[2].append([x, y])
elif (140 < x < 200) and (-100 < y < 0):
a[3].append([x, y])
elif (180 < x < 215) and (y < -200):
a[4].append([x, y])
elif (215 < x < 250) and (y < -200):
a[5].append([x, y])
sum_x = sum_y = 0 # Переменные для суммы абсцисс и ординат периферий
for i in a:
tx = ty = 0 # Координаты текущей периферии кластера
mx = -100000050000 # Максимальное расстояние
for j in i:
x1, y1 = j
sm = 0 # Суммарное расстояние
for k in i:
x2, y2 = k
sm += ((x2-x1)**2 + (y2-y1)**2)**0.5
if sm > mx:
mx = sm
tx, ty = x1, y1
sum_x += tx
sum_y += ty
print(int(abs(sum_x / 6)))
print(int(abs(sum_y / 6)))
Диаграмма для файла Б имеет вид:
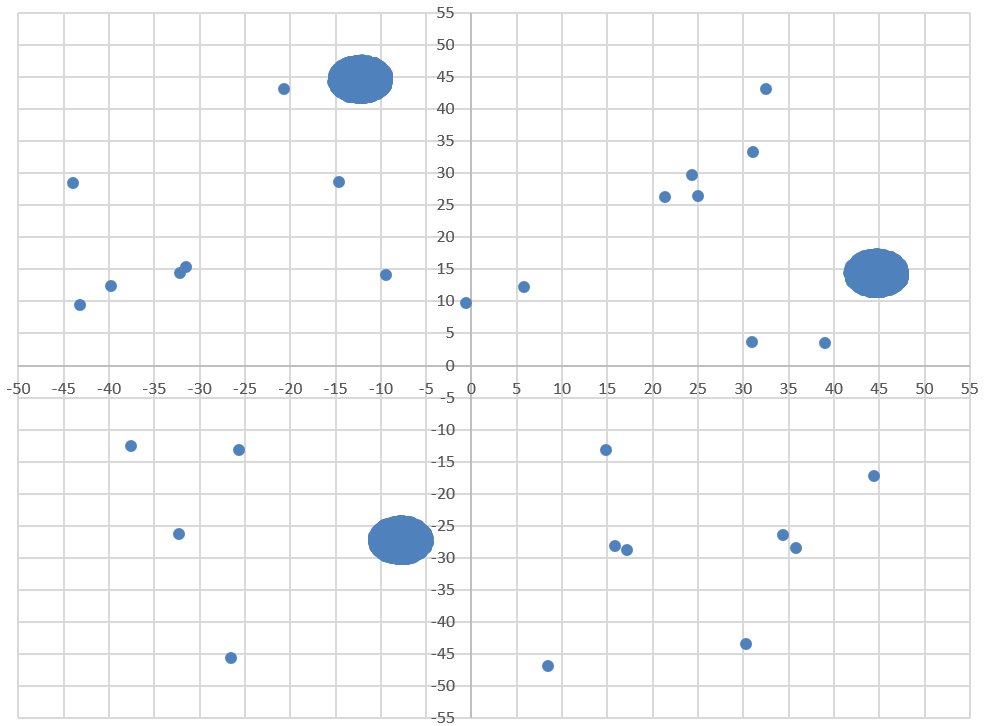
Рассмотрим все 3 кластера и координаты, в которых они находятся:
1) 
2) 
3)
Код программы для файла Б:
f = open(’5B.txt’)
n = f.readline() # Считываем первую строку файла с названиями столбцов
#распределение звезд на кластеры с помощью метода dbscan
# сохраняем массив данных
st = [list(map(float, i.replace(’,’, ’.’).split())) for i in f]
# подбираем по 1 звезде для каждого кластера меняя параметры в скобках
# for i in range(len(st)):
# if (40 < st[i][0] < 50 and 8 < st[i][1] < 20) and int(st[i][2]) % 2 != 0:
# print(i)
# break
a = [[[st[8000][0], st[8000][1]]], [[st[4003][0], st[4003][1]]], [[st[2][0], st[2][1]]]]
st.pop(8000), st.pop(4003), st.pop(2)
# отсеиваем все звезды с неподходящим блеском
for i in range(len(st)):
if int(st[i][2]) % 2 == 0:
st[i] = ’*’
# разделяем звезды на кластеры методом dbscan
for k in range(3):
for j in a[k]:
for i in range(len(st)):
if st[i] != ’*’:
p = [st[i][0], st[i][1]]
if dist(p, j) < 3 and int(st[i][2]) % 2 != 0:
a[k].append(p)
st[i] = ’*’
# распределение звезд на кластеры с помощью координат
a = [[] for i in range(3)] # Создаём список для кластеров
for line in f: # Считваем звёзды и определяем их к кластерам
x, y, m = list(map(float, line.replace(’,’, ’.’).split()))
if int(m) % 2 != 0:
if (-17 < x < -5) and (40 < y < 50):
a[0].append([x, y])
elif (40 < x < 50) and (8 < y < 20):
a[1].append([x, y])
elif (-15 < x < 0) and (-35 < y < -20):
a[2].append([x, y])
sum_x = sum_y = 0 # Переменные для суммы абсцисс и ординат периферий
for i in a:
tx = ty = 0 # Координаты текущей периферии кластера
mx = -100000050000 # Максимальное расстояние
for j in i:
x1, y1 = j
sm = 0 # Суммарное расстояние
for k in i:
x2, y2 = k
sm += ((x2-x1)**2 + (y2-y1)**2)**0.5
if sm > mx:
mx = sm
tx, ty = x1, y1
sum_x += tx
sum_y += ty
print(int(abs(sum_x / 3) * 500))
print(int(abs(sum_y / 3) * 500))


Специальные программы

Программа
лояльности v2.0
Приглашай друзей в Школково и получай вознаграждение до 10%!
Крути рулетку
и выигрывай призы!
Крути рулетку и покупай курсы со скидкой, которая привязывается к вашему аккаунту.

Бесплатное онлайн-обучение
Для школьников из приграничных территорий России, проживающих в ДНР, ЛНР, Херсонской, Запорожской, Белгородской, Курской, Брянской областях и Крыму.

Налоговые вычеты
Узнай, как получить налоговый вычет при оплате обучения в «Школково».
Специальное предложение
для учителей
Бесплатный доступ к любому курсу подготовки к ЕГЭ, ОГЭ и олимпиадам от «Школково». Мы с вами делаем общее и важное дело, а потому для нас очень значимо быть чем-то полезными для учителей по всей России!

Вернём деньги за курс
за твою сотку на ЕГЭ
Сдать экзамен на сотку и получить обратно деньги за подготовку теперь вполне реально!

