27.09 Анализ данных (звезды)
Ошибка.
Попробуйте повторить позже
Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба.
Кластер звёзд – это набор звёзд (точек) на графике, лежащий внутри круга радиусом  . Каждая звезда обязательно
принадлежит только одному из кластеров.
. Каждая звезда обязательно
принадлежит только одному из кластеров.
Истинный центр кластера, или центроид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера минимальна. Центроид не вычисляется для колец, он вычисляется только для кластеров, представляющих собой круг.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости,
которое вычисляется по формуле:
на плоскости,
которое вычисляется по формуле:

В файле A хранятся данные о звёздах двух кластеров, где  для внутреннего кластера и
для внутреннего кластера и  для
внешнего кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата
для
внешнего кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата
 , затем координата
, затем координата  . Значения даны в условных единицах, которые представлены вещественными числами.
Известно, что количество звёзд не превышает 1245.
. Значения даны в условных единицах, которые представлены вещественными числами.
Известно, что количество звёзд не превышает 1245.
В файле Б хранятся данные о звёздах трёх кластеров, где  для двух внутренних кластеров и
для двух внутренних кластеров и  для внешнего кластера. Известно, что количество звёзд не превышает 9414. Структура хранения информации о звездах
в файле Б аналогична файлу А.
для внешнего кластера. Известно, что количество звёзд не превышает 9414. Структура хранения информации о звездах
в файле Б аналогична файлу А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа:  —
среднее арифметическое абсцисс центров кластеров, и
—
среднее арифметическое абсцисс центров кластеров, и  – среднее арифметическое ординат центров
кластеров.
– среднее арифметическое ординат центров
кластеров.
В ответе запишите четыре числа через пробел: сначала целую часть произведения  для файла А и
для файла А и
 для файла А, далее целую часть произведения
для файла А, далее целую часть произведения  для файла Б и
для файла Б и  для файла
Б.
для файла
Б.
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.


Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  ,
перейдем в раздел «Вставка
,
перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
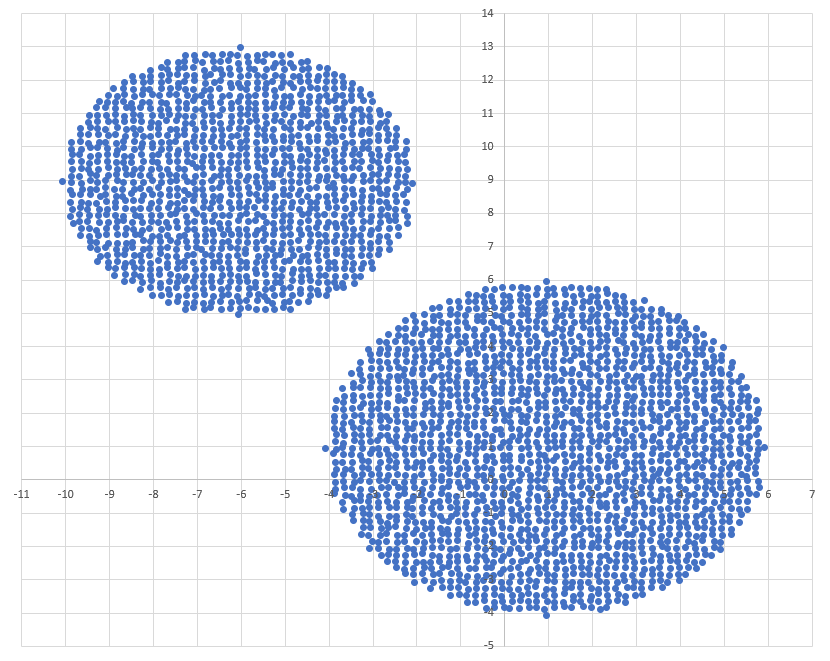
Диаграмма для файла А имеет вид:
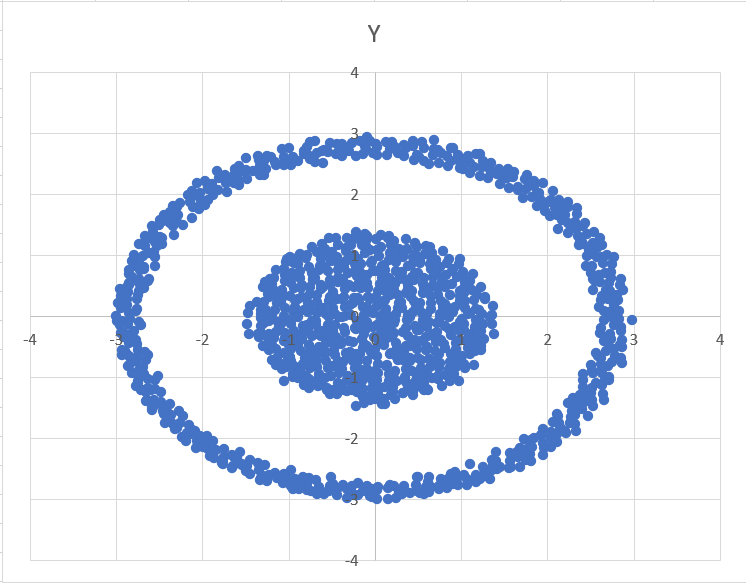
Внутренний кластер симметричен относительно оси Ox и Oy. Радиус внутреннего кластера равен 1.5,
соответственно, та или иная звезда будет принадлежать данному кластеру если она удовлетворяет следующему
неравенству окружности: 
Код программы для файла А:
f = open(’27_1_A.txt’) n = f.readline() cluster = [] # Создаём список для кластера for i in range(1245): # Считываем звёзды из файла star = list(map(float, f.readline().replace(’,’, ’.’).split())) if star[0] ** 2 + star[1] ** 2 <= 1.5**2: # Звезда относится к внутреннему кластеру cluster.append(star) tx = ty = 0 mn = 100000050000 for j in cluster: # Перебор предполагаемого центроида x1, y1 = j sm = 0 # Суммарное расстояние for k in cluster: # Перебор всех звёзд для вычисления суммарного расстояния x2, y2 = k sm += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5 if sm < mn: # У текущей звезды расстояние до остальных звёзд меньше предыдущей mn = sm tx, ty = x1, y1 # Сохранение нового центроида print(int(tx * 100)) print(int(ty * 100))
Диаграмма для файла Б имеет вид:
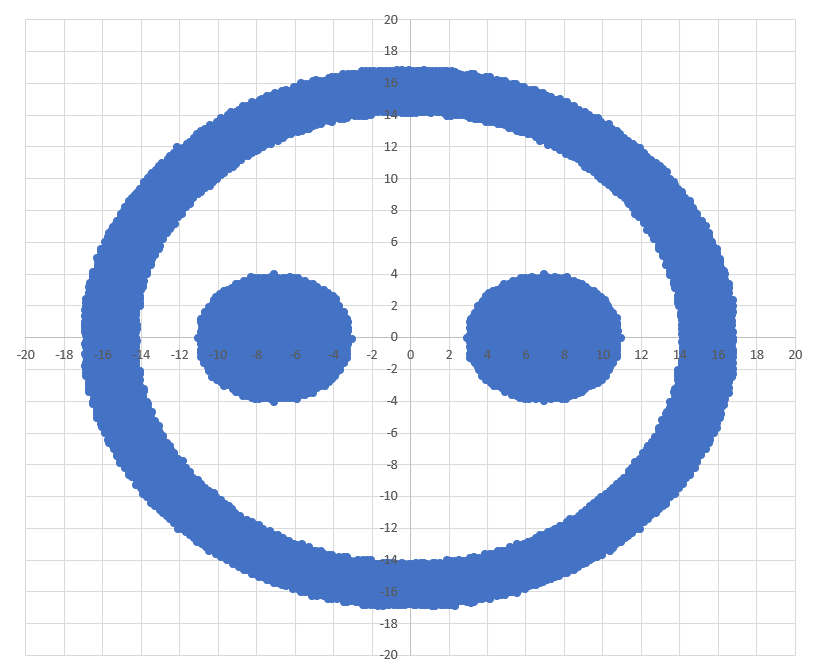
Определим подходящие уравнения окружностей, внутри которых лежат внутренние кластеры. Геометрические центры левого и правого кластеров находятся около точки (-7; 0) и (7; 0) соответственно, и для них можно выбрать радиус 4.5, не задевая внешний кластер. Получим следующие неравенства для внутренних кластеров:
 – для левого кластера
– для левого кластера
 – для правого кластера
– для правого кластера
Код программы для файла Б:
f = open(’27_1_B.txt’) n = f.readline() clusters = [[] for i in range(2)] for i in range(9414): star = list(map(float, f.readline().replace(’,’, ’.’).split())) if (star[0] - 7) ** 2 + star[1] ** 2 <= 4.5 ** 2: clusters[0].append(star) elif (star[0] + 7) ** 2 + star[1] ** 2 <= 4.5 ** 2: clusters[1].append(star) sum_x = sum_y = 0 for i in clusters: tx = ty = 0 mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 100)) print(int(sum_y / len(clusters) * 100))

Ошибка.
Попробуйте повторить позже
Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба.
Кластер звёзд – это набор звёзд (точек) на графике, лежащий внутри круга радиусом  . Каждая звезда обязательно
принадлежит только одному из кластеров.
. Каждая звезда обязательно
принадлежит только одному из кластеров.
Истинный центр кластера, или центроид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера минимальна.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости,
которое вычисляется по формуле:
на плоскости,
которое вычисляется по формуле:

В файле A хранятся данные о звёздах трёх кластеров, где  . В каждой строке записана информация о
расположении на карте одной звезды: сначала координата
. В каждой строке записана информация о
расположении на карте одной звезды: сначала координата  , затем координата
, затем координата  . Значения даны в условных
единицах, которые представлены вещественными числами. Известно, что количество звёзд не превышает
4119.
. Значения даны в условных
единицах, которые представлены вещественными числами. Известно, что количество звёзд не превышает
4119.
В файле Б хранятся данные о звёздах четырёх кластеров, где  . Известно, что количество
звёзд не превышает 11268. Структура хранения информации о звездах в файле Б аналогична файлу
А.
. Известно, что количество
звёзд не превышает 11268. Структура хранения информации о звездах в файле Б аналогична файлу
А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа:  —
среднее арифметическое абсцисс центров кластеров, и
—
среднее арифметическое абсцисс центров кластеров, и  – среднее арифметическое ординат центров
кластеров.
– среднее арифметическое ординат центров
кластеров.
В ответе запишите четыре числа через пробел: сначала целую часть произведения  для файла А и
для файла А и
 для файла А, далее целую часть произведения
для файла А, далее целую часть произведения  для файла Б и
для файла Б и  для файла
Б.
для файла
Б.
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.

Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  ,
перейдем в раздел «Вставка
,
перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
Диаграмма для файла А имеет вид:
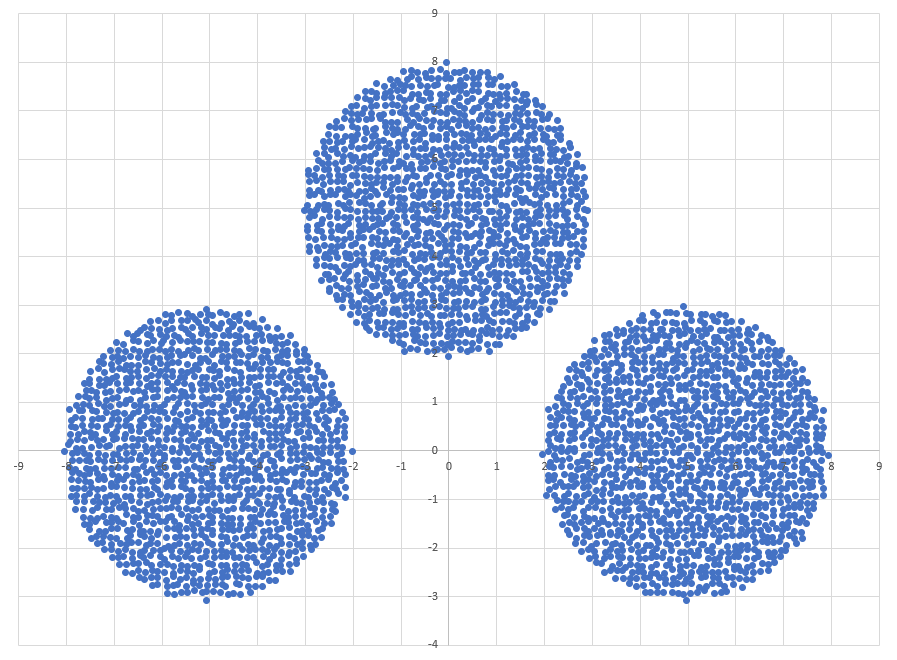
Нанесём на график две прямые:  и
и  :
:

Точки, находящиеся в пересечении неравенств:


принадлежат верхнему(первому) кластеру.
Точки, находящиеся в пересечении неравенств:


принадлежат левому(второму) кластеру.
Точки, находящиеся в пересечении неравенств:


принадлежат правому(третьему) кластеру.
Код программы для файла А:
f = open(’27_2_A.txt’) n = f.readline() clusters = [[] for i in range(3)] for i in range(4119): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x,y = star[0],star[1] if y >= x and y >= -x: clusters[0].append(star) elif y >= x and y <= - x: clusters[1].append(star) elif y <= x and y >= -x: clusters[2].append(star) sum_x = sum_y = tx = ty = 0 for i in clusters: mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2-x1)**2 + (y2-y1)**2)**0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 250)) print(int(sum_y / len(clusters) * 250))
Диаграмма для файла Б имеет вид:

Нанесём на график две прямые:  и
и  :
:

Теперь мы можем разделить кластеры. Точки, которые удовлетворяют пересечению неравенств:


принадлежат верхнему(первому) кластеру.
Точки, которые удовлетворяют пересечению неравенств:


принадлежат правому(второму) кластеру.
Точки, которые удовлетворяют пересечению неравенств:


принадлежат нижнему(третьему) кластеру.
Точки, которые удовлетворяют пересечению неравенств:


принадлежат левому(четвертому) кластеру.
Код программы для файла Б:
f = open(’27_2_B.txt’) n = f.readline() clusters = [[] for i in range(4)] for i in range(11268): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x,y = star[0],star[1] if y >= 0.5*x and y >= -0.5*x: clusters[0].append(star) elif y >= 0.5*x and y <= -0.5*x: clusters[1].append(star) elif y <= 0.5*x and y >= -0.5*x: clusters[2].append(star) elif y <= 0.5*x and y <= -0.5*x: clusters[3].append(star) sum_x = sum_y = tx = ty = 0 for i in clusters: mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2-x1)**2 + (y2-y1)**2)**0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 300)) print(int(sum_y / len(clusters) * 300))
Ошибка.
Попробуйте повторить позже
Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба.
Кластер звёзд – это набор звёзд (точек) на графике, лежащий внутри круга радиусом  . Каждая звезда обязательно
принадлежит только одному из кластеров.
. Каждая звезда обязательно
принадлежит только одному из кластеров.
Истинный центр кластера, или центроид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера минимальна.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости,
которое вычисляется по формуле:
на плоскости,
которое вычисляется по формуле:

В файле A хранятся данные о звёздах двух кластеров, где  у верхнего кластера и
у верхнего кластера и  у нижнего
кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата
у нижнего
кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата  ,
затем координата
,
затем координата  . Значения даны в условных единицах, которые представлены вещественными числами. Известно,
что количество звёзд не превышает 3215.
. Значения даны в условных единицах, которые представлены вещественными числами. Известно,
что количество звёзд не превышает 3215.
В файле Б хранятся данные о звёздах трёх кластеров, где  у левого кластера,
у левого кластера,  у верхнего кластера и
у верхнего кластера и
 у правого кластера. Известно, что количество звёзд не превышает 15682. Структура хранения информации о
звездах в файле Б аналогична файлу А.
у правого кластера. Известно, что количество звёзд не превышает 15682. Структура хранения информации о
звездах в файле Б аналогична файлу А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа:  —
среднее арифметическое абсцисс центров кластеров, и
—
среднее арифметическое абсцисс центров кластеров, и  – среднее арифметическое ординат центров
кластеров.
– среднее арифметическое ординат центров
кластеров.
В ответе запишите четыре числа через пробел: сначала целую часть произведения  для файла А и
для файла А и
 для файла А, далее целую часть произведения
для файла А, далее целую часть произведения  для файла Б и
для файла Б и  для файла
Б.
для файла
Б.
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.
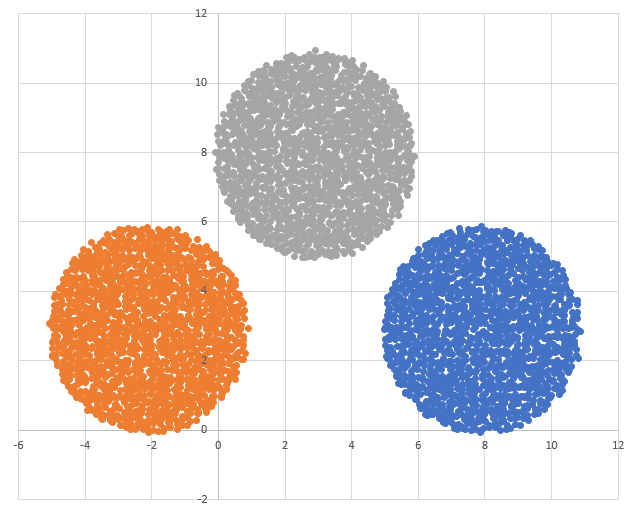
Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  ,
перейдем в раздел «Вставка
,
перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
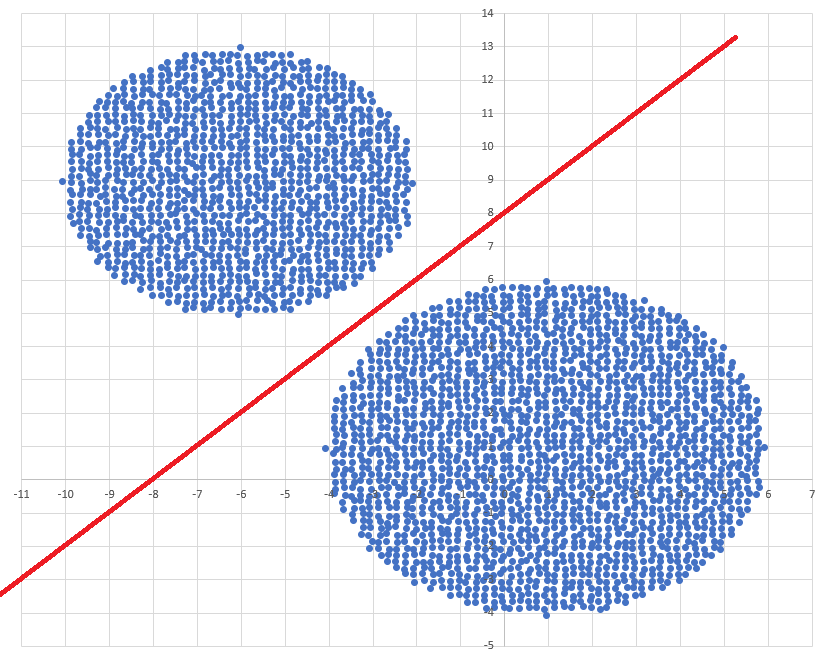
Диаграмма для файла А имеет вид:
Нанесём на график прямую:  :
:
Точки, которые удовлетворяют неравенству:  принадлежат верхнему(первому) кластеру. Все остальные -
нижнему(второму) кластеру.
принадлежат верхнему(первому) кластеру. Все остальные -
нижнему(второму) кластеру.
Код программы для файла А:
f = open(’27_3_A.txt’) n = f.readline() clusters = [[] for i in range(2)] for i in range(3215): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x,y = star[0],star[1] if y >= 8 + x: clusters[0].append(star) else: clusters[1].append(star) sum_x = sum_y = 0 for i in clusters: tx = ty = 0 mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2-x1)**2 + (y2-y1)**2)**0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 250)) print(int(sum_y / len(clusters) * 250))
Диаграмма для файла Б имеет вид:

Нанесём на график две прямые:  и
и  :
:

Теперь можем провести определить какие звезды к каким кластерам относятся.
Если точка находится в пересечении неравенств:  и
и  , то данная точка относится к верхнему
(первому) кластеру.
, то данная точка относится к верхнему
(первому) кластеру.
Если точка находится в пересечении неравенств:  и
и  , то данная точка относится к левому
(второму) кластеру.
, то данная точка относится к левому
(второму) кластеру.
Если точка находится в пересечении неравенств:  и
и  , то данная точка относится к правому
(третьему) кластеру.
, то данная точка относится к правому
(третьему) кластеру.
Код программы для файла Б:
f = open(’27_3_B.txt’) n = f.readline() clusters = [[] for i in range(3)] for i in range(15682): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x, y = star[0], star[1] if y >= 7 + x and y >= -6 - x: clusters[0].append(star) elif y >= 7 + x and y <= -6 - x: clusters[1].append(star) elif y <= 7 + x and y >= -6 - x: clusters[2].append(star) sum_x = sum_y = 0 for i in clusters: tx = ty = 0 mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 300)) print(int(sum_y / len(clusters) * 300))
Ошибка.
Попробуйте повторить позже
Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба.
Кластер звёзд – это набор звёзд (точек) на графике, лежащий внутри круга радиусом  . Каждая звезда обязательно
принадлежит только одному из кластеров.
. Каждая звезда обязательно
принадлежит только одному из кластеров.
Истинный центр кластера, или центроид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера минимальна. Центроид не вычисляется для колец, он вычисляется только для кластеров, представляющих собой круг.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости,
которое вычисляется по формуле:
на плоскости,
которое вычисляется по формуле:

В файле A хранятся данные о звёздах трёх кластеров, где  для нижнего кластера и для верхнего
внешнего кластера и
для нижнего кластера и для верхнего
внешнего кластера и  для верхнего внутреннего кластера. В каждой строке записана информация о
расположении на карте одной звезды: сначала координата
для верхнего внутреннего кластера. В каждой строке записана информация о
расположении на карте одной звезды: сначала координата  , затем координата
, затем координата  . Значения даны в условных
единицах, которые представлены вещественными числами. Известно, что количество звёзд не превышает
966.
. Значения даны в условных
единицах, которые представлены вещественными числами. Известно, что количество звёзд не превышает
966.
В файле Б хранятся данные о звёздах четырёх кластеров,  для нижнего правого кластера и для верхнего
внешнего кластера и
для нижнего правого кластера и для верхнего
внешнего кластера и  для верхнего внутреннего кластера и
для верхнего внутреннего кластера и  для нижнего левого кластера. Известно, что
количество звёзд не превышает 4798. Структура хранения информации о звездах в файле Б аналогична файлу
А.
для нижнего левого кластера. Известно, что
количество звёзд не превышает 4798. Структура хранения информации о звездах в файле Б аналогична файлу
А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа:  —
среднее арифметическое абсцисс центров кластеров, и
—
среднее арифметическое абсцисс центров кластеров, и  – среднее арифметическое ординат центров
кластеров.
– среднее арифметическое ординат центров
кластеров.
В ответе запишите четыре числа через пробел: сначала целую часть произведения  для файла А и
для файла А и
 для файла А, далее целую часть произведения
для файла А, далее целую часть произведения  для файла Б и
для файла Б и  для файла
Б.
для файла
Б.
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.
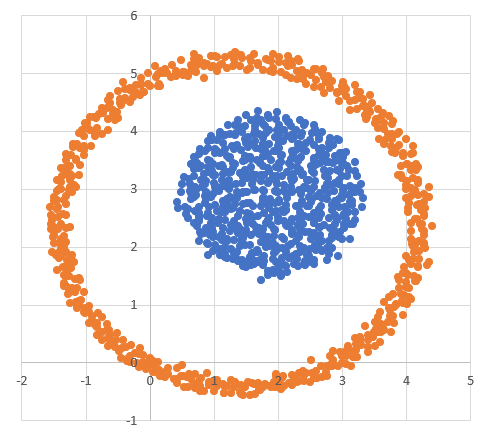
Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  ,
перейдем в раздел «Вставка
,
перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
Диаграмма для файла А имеет вид:

Рассмотрим подробно нижний кластер. Он симметричен относительно оси Oy и Ox. Его радиус равен  .
Следовательно, если координаты точки удовлетворяют неравенству окружности:
.
Следовательно, если координаты точки удовлетворяют неравенству окружности:  , значит, это точка
принадлежит нижнему кластеру.
, значит, это точка
принадлежит нижнему кластеру.
Изучим верхний внутренний кластер, его радиус равен  . Центр круга находится в точке (-5;4). Следовательно,
если координаты точки удовлетворяют неравенству окружности:
. Центр круга находится в точке (-5;4). Следовательно,
если координаты точки удовлетворяют неравенству окружности:  , значит, это точка
принадлежит верхнему внутреннему кластеру.
, значит, это точка
принадлежит верхнему внутреннему кластеру.
Если точка не удовлетворяет ни одному из выше описанных неравенств, значит, она находится во внешнем кластере (кольце). Поскольку мы не высчитываем центроид колец, то данные точки нас не интересуют.
Код программы для файла А:
f = open(’27_4_A.txt’) n = f.readline() clusters = [[] for i in range(2)] for i in range(966): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x,y = star[0],star[1] if x**2 + y ** 2 <= 9: clusters[0].append(star) elif (x + 5)**2 + (y - 4) ** 2 <= 4: clusters[1].append(star) sum_x = sum_y = tx = ty = 0 for i in clusters: mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2-x1)**2 + (y2-y1)**2)**0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 333)) print(int(sum_y / len(clusters) * 666))
Диаграмма для файла Б имеет вид:
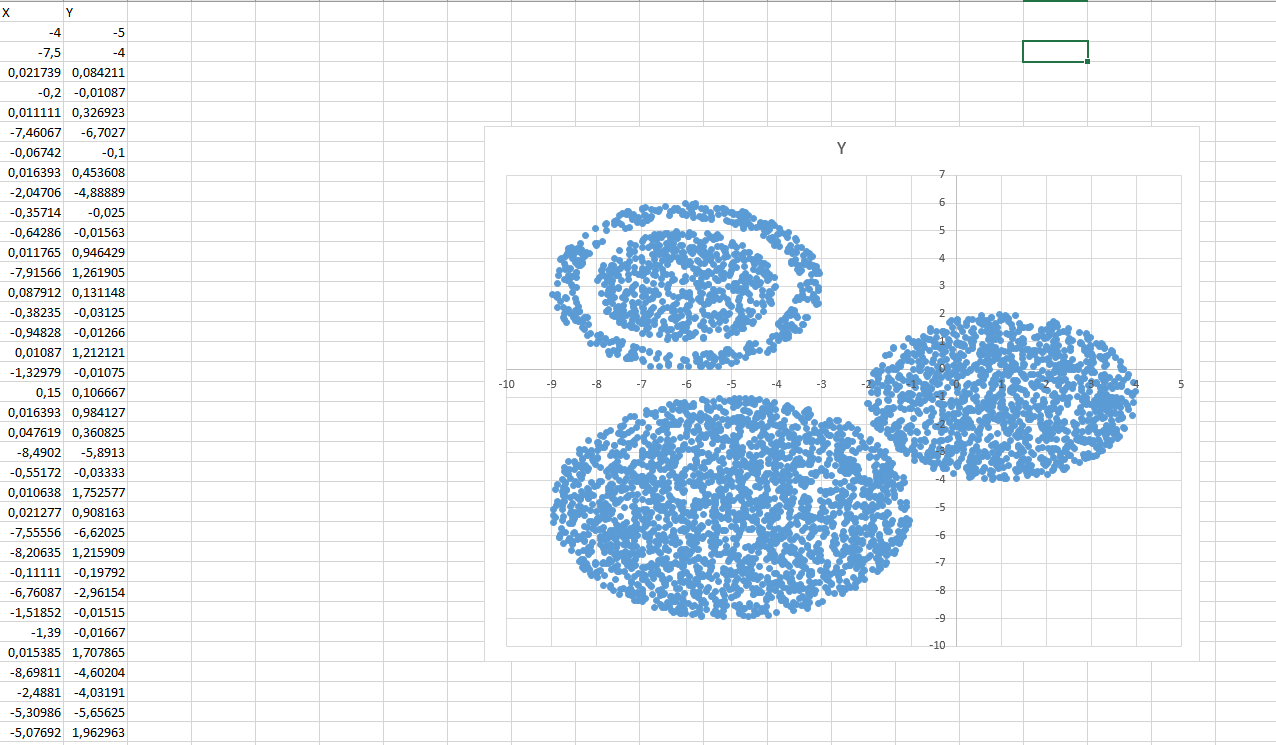
Разберем подробнее нижний правый кластер. Центр круга находится в точке (1;-1). Его радиус равен  .
Следовательно, если координаты точки удовлетворяют неравенству окружности:
.
Следовательно, если координаты точки удовлетворяют неравенству окружности:  , значит, это
точка принадлежит нижнему правому кластеру.
, значит, это
точка принадлежит нижнему правому кластеру.
Изучим поподробнее нижний левый кластер. Центр круга находится в точке (-5;-5). Его радиус равен  .
Следовательно, если координаты точки удовлетворяют неравенству окружности:
.
Следовательно, если координаты точки удовлетворяют неравенству окружности:  , значит, это
точка принадлежит нижнему левому кластеру.
, значит, это
точка принадлежит нижнему левому кластеру.
Рассмотрим верхний внутренний кластер. Центр круга находится в точке (-6;3). Его радиус равен  .
Следовательно, если координаты точки удовлетворяют неравенству окружности:
.
Следовательно, если координаты точки удовлетворяют неравенству окружности:  , значит, это
точка принадлежит верхнему внутреннему кластеру.
, значит, это
точка принадлежит верхнему внутреннему кластеру.
Если точка не удовлетворяет ни одному из выше описанных неравенств, значит, она находится во внешнем кластере (кольце). Поскольку мы не высчитываем центроид колец, то данные точки нас не интересуют.
Код программы для файла Б:
f = open(’27_4_B.txt’) n = f.readline() clusters = [[] for i in range(3)] for i in range(4798): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x,y = star[0],star[1] if ((x - 1) ** 2 + (y + 1) ** 2) <= 9: clusters[0].append(star) elif ((x - (-6)) ** 2 + (y - 3) ** 2) <= 4: clusters[1].append(star) elif ((x + 5)**2 + (y + 5)**2) <= 16: clusters[2].append(star) sum_x = sum_y = tx = ty = 0 for i in clusters: mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2-x1)**2 + (y2-y1)**2)**0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 321)) print(int(sum_y / len(clusters) * 123))
Ошибка.
Попробуйте повторить позже
Учёный решил провести кластеризацию некоторого множества звёзд по их расположению на карте звёздного неба.
Кластер звёзд – это набор звёзд (точек) на графике, лежащий внутри круга радиусом  . Каждая звезда обязательно
принадлежит только одному из кластеров.
. Каждая звезда обязательно
принадлежит только одному из кластеров.
Истинный центр кластера, или центроид, – это одна из звёзд на графике, сумма расстояний от которой до всех остальных звёзд кластера минимальна. Центроид не вычисляется для колец, он вычисляется только для кластеров, представляющих собой круг.
Под расстоянием понимается расстояние Евклида между двумя точками  и
и  на плоскости,
которое вычисляется по формуле:
на плоскости,
которое вычисляется по формуле:

В файле A хранятся данные о звёздах двух кластеров, где  у внутреннего кластера и
у внутреннего кластера и  у внешнего
кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата
у внешнего
кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата  ,
затем координата
,
затем координата  . Значения даны в условных единицах, которые представлены вещественными числами. Известно,
что количество звёзд не превышает 1029.
. Значения даны в условных единицах, которые представлены вещественными числами. Известно,
что количество звёзд не превышает 1029.
В файле Б хранятся данные о звёздах четырёх кластеров, где  у внутренних кластеров,
у внутренних кластеров,  у
внешних кластеров. Известно, что количество звёзд не превышает 8166. Структура хранения информации о звездах в
файле Б аналогична файлу А.
у
внешних кластеров. Известно, что количество звёзд не превышает 8166. Структура хранения информации о звездах в
файле Б аналогична файлу А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа:  —
среднее арифметическое абсцисс центров кластеров, и
—
среднее арифметическое абсцисс центров кластеров, и  – среднее арифметическое ординат центров
кластеров.
– среднее арифметическое ординат центров
кластеров.
В ответе запишите четыре числа через пробел: сначала целую часть произведения  для файла А и
для файла А и
 для файла А, далее целую часть произведения
для файла А, далее целую часть произведения  для файла Б и
для файла Б и  для файла
Б.
для файла
Б.
Возможные данные одного из файлов иллюстрированы графиком.
Внимание! График приведён в иллюстративных целях для произвольных значений, не имеющих отношения к заданию. Для выполнения задания используйте данные из прилагаемого файла.
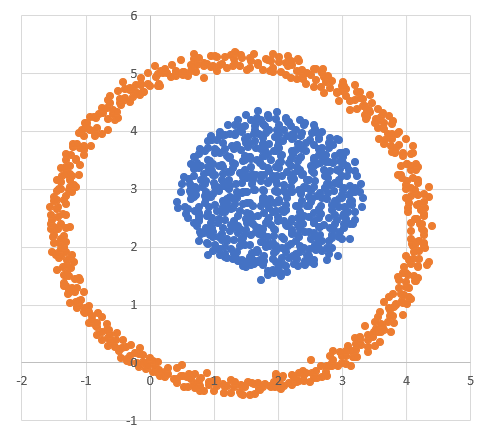
Для начала визуально оценим данные в условии кластеры. Для этого откроем предложенные файлы в  ,
перейдем в раздел «Вставка
,
перейдем в раздел «Вставка  Диаграммы
Диаграммы  Точечная».
Точечная».
Диаграмма для файла А имеет вид:
Определим уравнение окружности, внутри которой лежит внутренний кластер. Геометрический центр внутреннего
кластера находится приблизительно в точке (0;3.5). Значит, если координаты точки удовлетворяют неравенству
окружности:  , тогда эта звезда относится ко внутреннему кластеру.
, тогда эта звезда относится ко внутреннему кластеру.
Код программы для файла А:
f = open(’27_5_A.txt’) n = f.readline() cluster = [] for i in range(1029): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x, y = star[0], star[1] if x ** 2 + (y - 3.5) ** 2 <= 2.1 ** 2: cluster.append(star) sum_x = sum_y = tx = ty = 0 mn = 100000050000 for j in cluster: x1, y1 = j sm = 0 for k in cluster: x2, y2 = k sm += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x * 525)) print(int(sum_y * 525))
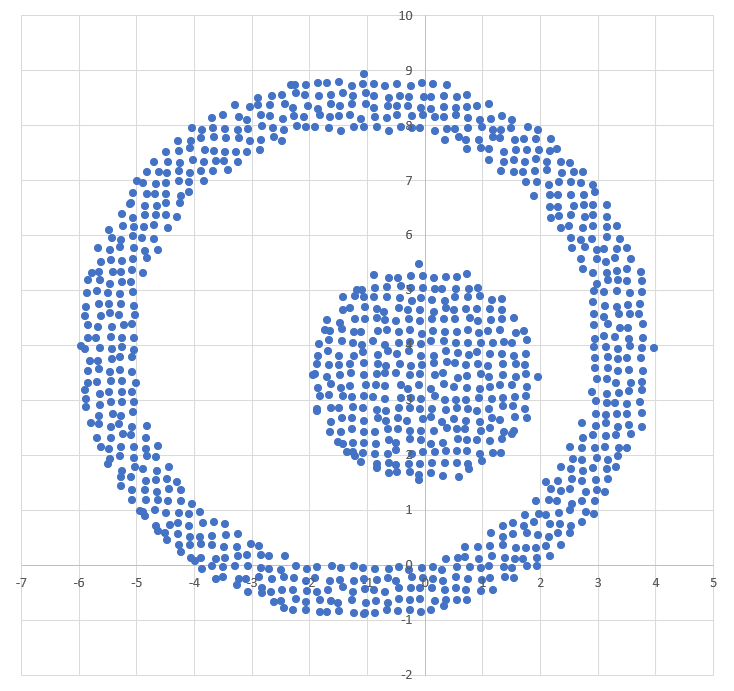
Диаграмма для файла Б имеет вид:

Нанесём на график прямую:  :
:

Теперь можем провести определить какие звезды к каким кластерам относятся.
Сначала разделим на группы по два кластера.
Точки, которые удовлетворяют неравенству:  находятся в верхней (первой) группе.
находятся в верхней (первой) группе.
Точки, которые удовлетворяют неравенству:  находятся в нижней (второй) группе.
находятся в нижней (второй) группе.
Рассмотрим подробно первую группу:
Радиус внутренний кластер равен  , геометрический центр кластера находится в точке (8;7). Следовательно, если
координаты точки удовлетворяют неравенству окружности:
, геометрический центр кластера находится в точке (8;7). Следовательно, если
координаты точки удовлетворяют неравенству окружности:  , тогда эта звезда относится ко
внутреннему кластеру первой группы.
, тогда эта звезда относится ко
внутреннему кластеру первой группы.
Рассмотрим подробно вторую группу:
Радиус внутренний кластер равен  , геометрический центр кластера находится в точке (2;2). Следовательно, если
координаты точки удовлетворяют неравенству окружности:
, геометрический центр кластера находится в точке (2;2). Следовательно, если
координаты точки удовлетворяют неравенству окружности:  , тогда эта звезда относится ко
внутреннему кластеру второй группы.
, тогда эта звезда относится ко
внутреннему кластеру второй группы.
Код программы для файла Б:
f = open(’27_3_B.txt’) n = f.readline() clusters = [[] for i in range(2)] for i in range(8166): star = list(map(float, f.readline().replace(’,’, ’.’).split())) x, y = star[0], star[1] if y >= 9.5 - x: if (x - 8) ** 2 + (y - 7) ** 2 < 2.1 ** 2: clusters[0].append(star) else: if (x - 2) ** 2 + (y - 2) ** 2 < 2.1 ** 2: clusters[1].append(star) sum_x = sum_y = 0 for i in clusters: tx = ty = 0 mn = 100000050000 for j in i: x1, y1 = j sm = 0 for k in i: x2, y2 = k sm += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5 if sm < mn: mn = sm tx, ty = x1, y1 sum_x += tx sum_y += ty print(int(sum_x / len(clusters) * 300)) print(int(sum_y / len(clusters) * 300))


